
Withdraw PF Amount Online: In today's dynamic world, financial independence is not just a goal but a necessity. One significant aspect of securing your financial future is managing your Provident Fund
The Ultimate Guide: How to Create an EPF Online Account 2024

EPF Online Account : In today's digital age, managing your finances has become easier than ever. One essential aspect of financial planning for employees in India is the Employees Provident Fund (EPF)
How to Apply for TNPSC Group 4 Exam Online

TNPSC Group 4 Exam: The Tamil Nadu Public Service Commission (TNPSC) conducts various recruitment exams to fill government vacancies in the state. One such prominent examination is the TNPSC Group
How to Fill Post Office Savings Account KYC Form in Tamil Nadu 2024

Post Office Savings Account KYC form: Know Your Customer (KYC) is a crucial process that financial institutions, including post offices, undertake to verify the identity of their customers. If you
How to Open a Post Office Savings Account 2024

Post office savings account: In the pursuit of financial security and stability, many individuals explore various avenues for saving money. One often overlooked option is opening a savings account
How to check Kalaignar Magalir Urimai Thogai Scheme Application Status online 2024
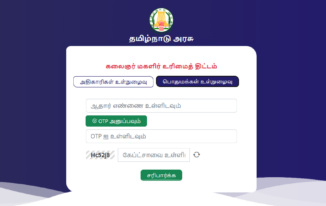
Check Kalaignar Magalir Urimai Thogai Scheme Application Status online: The Chief Minister of Tamil Nadu initiated the Kalaignar Magalir Urimai Thogai Scheme, which disburses Rs 1,000 monthly to
How to use Sim Network Unlock Pin Free Software Tool to unlock SIM lock 2024
Free sim network unlock pin software: Solve the sim network unlock pin screen now! Is there any way to deactivate the SIM lock off a Cell phone? This question was asked by many Cell phone users and
How to Share Your Location on WhatsApp 2024

How to Share Your Location on WhatsApp: WhatsApp, a widely used messaging platform, offers a convenient feature that allows users to share their live location with friends, family, or
How to download WhatsApp status without any App 2024

Download WhatsApp status, WhatsApp doesn't provide a built-in feature to download the status updates (photos or videos) shared by your contacts. WhatsApp's status feature is designed to be temporary,
How to Registering a Domain Name for Your Website in 2024

Registering a domain name is an essential step when establishing your online presence. A domain name serves as your unique web address, allowing users to find and access your website. In this